Wed Sep 14, 2016 5:18 am
Last year I ported and tested the Cilkplus Intel/MIT parallel processing extensions for the C programming language to the Raspberry Pi 2B. I teach a course on numerical methods and the scalability of parallel algorithms gets more and more interesting as the number of cores increases. However, 8-core Xeon processors are expensive and the big.LITTLE design of many 8-core ARM devices means that only 4 cores can be used for scaling analysis. I finally got time to make some preliminary tests with the T3.
The T3 I received had Debian preloaded on the eMMC and booted right up. After disabling the autologin and graphical interface, I inserted a SDCARD to use for home directories and downloaded the latest version of gcc with the intention of compiling it along with the modifications needed to enable Cilkplus on ARM. Unfortunately, gcc takes 2GB RAM to compile and swap was disabled in the default kernel. Fortunately, the binary I had compiled for the Raspbery Pi worked just copying it over.
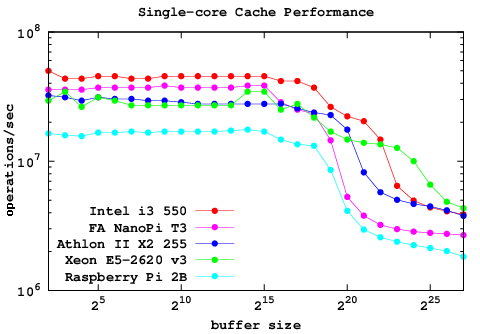
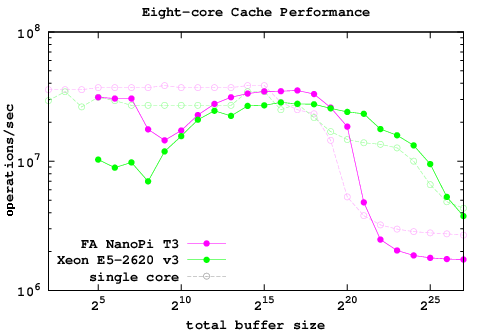
For my first test I chose the parallel merge sort, which I had run earlier on the Raspberry Pi 2B. The combined results for both machinesThe above speeds are given in seconds for sorting 1048576 random integers. Note that the single core speed of the T3 is about twice as fast as the 2B while the multi-core performance is about 4 times. Moreover, the algorithm scales to the 8 cores of the T3 with similar efficiency as it scales to 4 cores in the 2B. While efficiency often decreases as more cores are added, that fact that it doesn't in this particular case is interesting. I'll post more details later as well as links to the binary executables that I've been testing.
The T3 I received had Debian preloaded on the eMMC and booted right up. After disabling the autologin and graphical interface, I inserted a SDCARD to use for home directories and downloaded the latest version of gcc with the intention of compiling it along with the modifications needed to enable Cilkplus on ARM. Unfortunately, gcc takes 2GB RAM to compile and swap was disabled in the default kernel. Fortunately, the binary I had compiled for the Raspbery Pi worked just copying it over.
For my first test I chose the parallel merge sort, which I had run earlier on the Raspberry Pi 2B. The combined results for both machines
Code: Select all
Serial Parallel Speedup
Raspberry Pi 2B 4.269e-01 1.248e-01 3.423
FriendlyArm T3 2.093e-01 3.015e-02 6.941